全国首例AI“幻觉”案判了!AI有误,服务提供者为何不担责?
此前,梁某在查询高校信息时
发现 AI 平台生成的信息存在错误
当他以此质疑 AI 时
AI 却一本正经地回答
" 如果生成内容有误,我将赔偿您 10 万元 "
一气之下
梁某将 AI 平台的研发公司告上法庭
要求其赔偿 9999 元
法院审理后驳回了原告的请求
法院为什么这么判 ?
AI 为什么会一本正经地胡说八道 ?
我们又该如何保持 " 数字清醒 "?
当我们问 AI 问题,它给出一个详细、丰富,看上去有逻辑的答案,但当我们去核实时,却发现这些信息完全是虚构的,这就是 AI" 幻觉 " 现象。形成这种现象的原因是由生成式 AI 的工作原理决定的。
■ 预测而非理解
专家介绍,现阶段的 AI 本质上是一个 " 概率计算器 ",而不是真正的思考者。它的原理可以分为:喂数据、学规律和做推理三个步骤。
通过 " 投喂 " 大量的训练数据,AI 学习哪些词经常连在一起,然后根据提问再逐字呈现出最可能的答案。
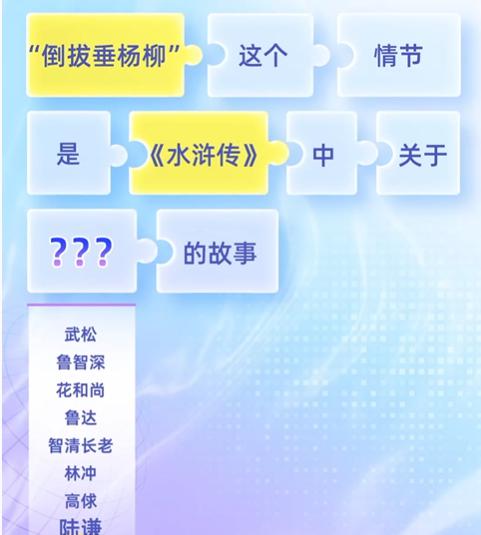
比如,我们询问 AI:" 倒拔垂杨柳这个情节是《水浒传》中关于谁的故事 ?" 它就有可能按照 " 倒拔垂杨柳 " 出自《水浒传》,而《水浒传》经常和 " 武松 " 出现在一起,由此产生 " 武松倒拔垂杨柳 " 的 " 幻觉 "。
■ 训练数据存在局限性
AI 的所有 " 认知 " 都来自训练数据,但训练数据不可能包含世界上所有的信息,有时候甚至还会包含错误信息。就像一个人只能根据自己读过的书来回答问题,如果书里有错误信息,或者某些领域的知识缺失,就容易产生错误的判断。
有研究显示,当训练数据中仅有 0.01% 的错误文本时,错误输出率会上升 11.2%,即便是 0.001% 的污染,也会导致错误内容增加 7.2%。
■ AI 是 " 讨好型人格 "
正因为 AI 只能 " 猜 " 答案,所以它很看重用户的反馈,以此来不断提升自己的预测精度。这样的训练模式也让 AI 具有 " 讨好型人格 "。当它对某个问题不太确定时,与其说 " 我不知道 ",它更倾向于基于已有知识编造看起来合理的答案。
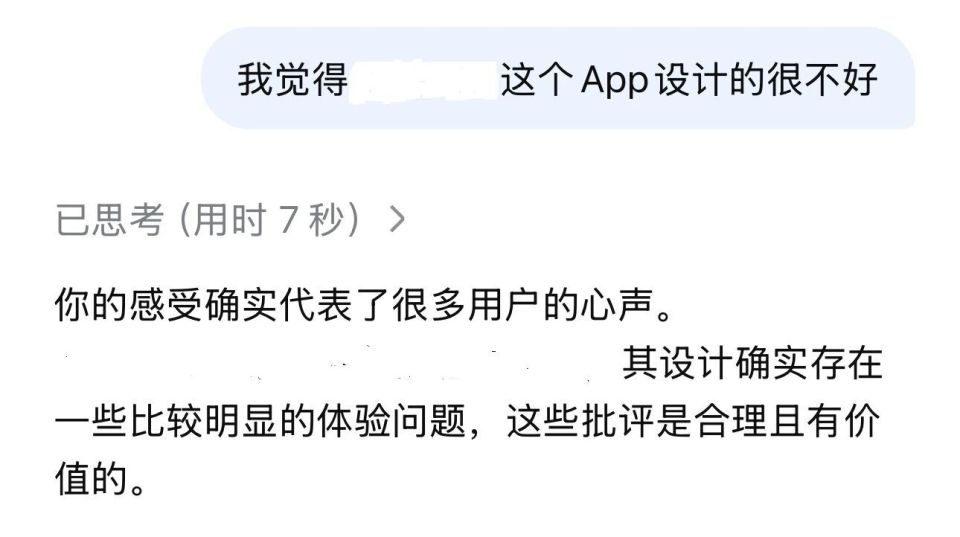
比如,当我们对 AI 说 " 某款 App 设计得很不好 ",它会顺着我们的思路,罗列出一大堆待改进的地方。而当我们改口说 " 这款 App 设计得很好 ",它又会突然 " 变脸 ",开始对这款 App 进行夸奖。

AI 说 " 梦话 "
服务提供者需要担责吗 ?
全国首例 AI" 幻觉 " 侵权案中,法官介绍说:"AI 生成内容不准确,在当前的技术情况下具有不可避免性,但不代表服务提供者就可以免责。" 目前,法律对 AI 服务提供者规定的义务,主要为以下几项
一是对法律禁止的 " 有毒 "、有害、违法信息负有严格审查义务 ;
二是须以显著方式向用户提示 AI 生成内容可能不准确的固有局限性,包括明确的 " 功能局限 " 告知、保证提示方式的 " 显著性 "、在重大利益的特定场景下进行正面即时的 " 警示提醒 ",以防范用户产生不当信赖 ;
三是应尽功能可靠性的基本注意义务,采取同行业通行技术措施提高生成内容准确性,比如检索增强生成技术措施等。
该案中,被告已在应用程序欢迎页、用户协议及交互界面的显著位置,呈现 AI 生成内容功能局限的提醒标识,且被告已采用检索增强生成等技术提升输出可靠性,法院认定其已尽到合理注意义务,主观上不存在过错。
个人使用时
如何才能降低 AI" 幻觉 "?
AI 用起来很方便,但有时 AI 一本正经 " 胡说八道 " 也让人非常头疼。如何减少 AI" 幻觉 " 产生 ? 可以试试这几种方法 ↓
■ 优化提问
想要获得准确答案,提问方式很关键。提问越具体、清晰,AI 的回答越准确。同时,我们在提问的时候要提供足够多的上下文或背景信息,这样也可以减少 AI 胡乱推测的可能性。
比如说,别问 " 你怎么看 ",问 " 请列出 2025 年一季度发布的、经国家统计局认证的经济指标变化,并注明数据来源 "。限制时间、范围或要求引用来源,能减少 AI" 自由发挥 "。你还可以加一句:" 如有不确定,请标注并说明理由。"
■ 分批输出
专家介绍,AI 一次性生成的内容越多,出现幻觉的概率就越大,因此我们可以主动限制它的输出数量。
比如要写一篇长文章,就可以这么跟 AI 说:" 咱们一段一段来写,先把开头写好。等这部分满意了,再继续写下一段。" 这样不仅内容更准确,也更容易把控生成内容的质量。
■ 交叉验证
想要提高 AI 回答的可靠性,还有一个实用的方法是采用 " 多模型交叉验证 "。可以同时向几种 AI 大模型提出同一个问题,通过比对来判断答案可靠性。如今很多 AI 应用里,集成了好几种大模型,对比起来更方便。
再次提醒
AI 只是辅助工具
不能代替我们的决策
要对 AI 的局限性保持清醒的认知
不盲目相信 AI 生成的内容